
Hoe meet ik de nauwkeurigheid van prognoses?
Het meten van de nauwkeurigheid van prognoses is van cruciaal belang voor benchmarking en het continu verbeteren van uw prognoseproces. Maar waar beginnen we? Dit artikel onderzoekt waarom we nauwkeurigheid moeten meten, wat we moeten bijhouden en de belangrijkste statistieken die we moeten begrijpen om de gegevens te begrijpen.
Waarom zou ik de nauwkeurigheid van prognoses meten?
1. Om uw prognoseproces te verbeteren, moet u de nauwkeurigheid kunnen volgen.
Forecasting moet worden gezien als een continu verbeteringsproces. Uw planners moet voortdurend streven naar verbetering van het prognoseproces en de prognosenauwkeurigheid. Om dit te doen, moet u weten wat werkt en wat niet.
Veel organisaties genereren bijvoorbeeld basisprognoses met behulp van statistische benaderingen en passen deze vervolgens op oordeelsbasis aan om hun kennis van toekomstige gebeurtenissen vast te leggen. Organisaties die de nauwkeurigheid van zowel de statistische als aangepaste prognoses bijhouden, leren waar de aanpassingen de prognoses verbeteren en waar ze deze verslechteren. Met deze kennis kunnen zij hun tijd en aandacht richten op de zaken waar de aanpassingen waarde toevoegen.
2. Trackingnauwkeurigheid geeft inzicht in verwachte prestaties.
Een prognose is meer dan een getal. Om een prognose effectief te gebruiken, moet u inzicht hebben in de verwachte nauwkeurigheid.
Statistieken binnen de steekproef en betrouwbaarheidslimieten geven enig inzicht in de verwachte nauwkeurigheid; ze onderschatten echter bijna altijd de feitelijke (out-of-sample) voorspellingsfout. Dit is te wijten aan het feit dat de parameters van een statistisch model worden geselecteerd om de aangepaste fout over de historische gegevens te minimaliseren. De parameters zijn dus aangepast aan de historische gegevens en weerspiegelen al hun eigenaardigheden. Anders gezegd, het model is geoptimaliseerd voor het verleden, niet voor de toekomst.
Over het algemeen leveren out-of-sample-statistieken (d.w.z. historische voorspellingsfouten) een betere maatstaf voor de verwachte voorspellingsnauwkeurigheid dan inside-sample-statistieken.
3. Met trackingnauwkeurigheid kunt u uw prognoses benchmarken.
Als u het geluk heeft in een branche te zitten met gepubliceerde statistieken over de nauwkeurigheid van prognoses, geeft het vergelijken van uw nauwkeurigheid met deze benchmarks inzicht in de effectiviteit van uw prognoses. Als er geen branchebenchmarks beschikbaar zijn (meestal het geval), kunt u door periodiek uw huidige prognosenauwkeurigheid te vergelijken met uw eerdere prognosenauwkeurigheid uw verbetering meten.
4. Door de nauwkeurigheid van prognoses te bewaken, kunt u problemen vroegtijdig opsporen.
Een abrupte onverwachte verandering in de nauwkeurigheid van de prognose is vaak het resultaat van een onderliggende gebeurtenis. Als een belangrijke klant bijvoorbeeld buiten uw medeweten besluit om een concurrerend product op de markt te brengen, kan uw eerste indicatie een ongewoon grote voorspellingsfout zijn. Door prognosefouten routinematig te monitoren, kunt u deze veranderingen in een vroeg stadium opsporen, onderzoeken en erop reageren, voordat ze grotere problemen worden.
Een prognose archief bouwen
Het bijhouden van de nauwkeurigheid van prognoses vereist dat u een record bijhoudt van eerder gegenereerde prognoses. Dit record van de eerder gegenereerde prognoses wordt het prognosearchief genoemd.

De bovenstaande tabel toont een zeer eenvoudig prognosearchief voor een enkel product. De eerste rij bevat de prognose die in november 2019 is gegenereerd. De tweede rij bevat de prognose die in december 2019 is gegenereerd, enz.
Als uw prognoseproces meerdere prognoses genereert (bijv. statistische prognose, aangepaste prognose, prognose van de verkoper, enz.), dan moeten alle prognoses worden opgeslagen in het prognosearchief.
Zodra het archief is opgezet, kan het worden gebruikt om rapporten te genereren waarin de gearchiveerde prognoses worden vergeleken met de daadwerkelijke verkopen. Vanwege het volume en de complexiteit van de gegevens kan dit het beste worden bereikt met behulp van een speciale softwareoplossing zoals Forecast Pro TRAC of een intern ontwikkelde oplossing die gebruikmaakt van een relationele database – het is geen taak voor Excel.
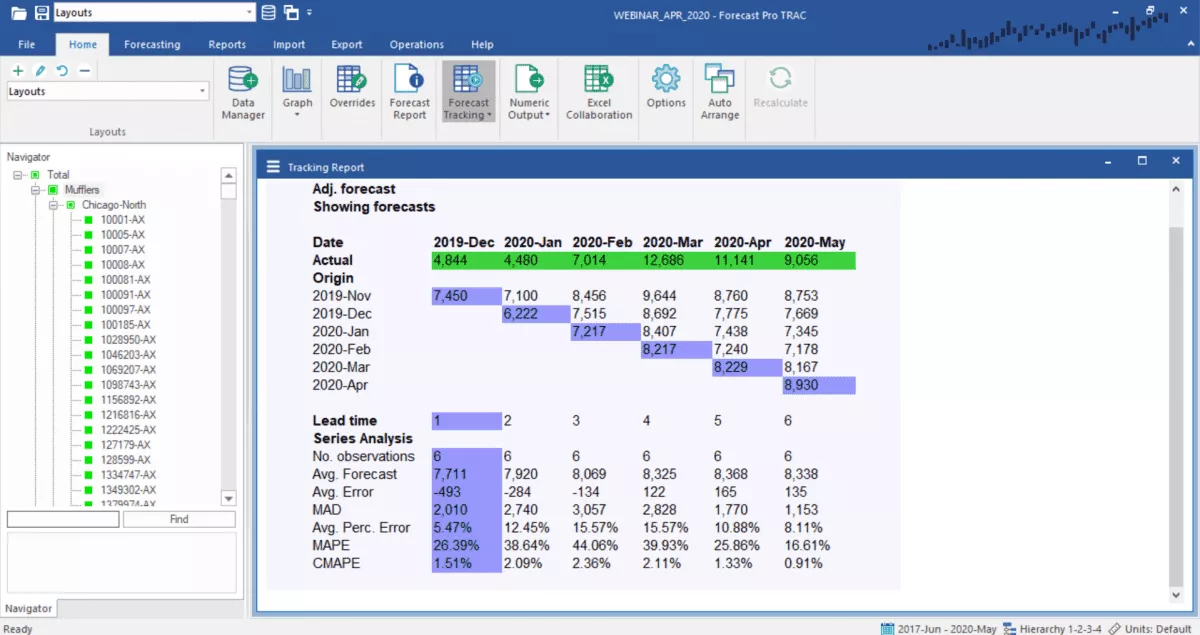
De bovenstaande schermafbeelding toont een voorbeeldrapport voor het bijhouden van nauwkeurigheid. Vanwege het trapsgewijze uiterlijk wordt dit stijlrapport vaak een watervalrapport genoemd. De bovenste helft van het numerieke gedeelte (het gedeelte “Prognoserapport”) toont de actuele vraaggeschiedenis en de gearchiveerde prognoses voor de periodes die worden geanalyseerd. De onderste helft toont samenvattende statistieken voor verschillende doorlooptijden.
Een korte handleiding voor prognosenauwkeurigheidsstatistieken en hoe deze te gebruiken
MAPE
De MAPE (Mean Absolute Percent Error) meet de grootte van de fout in procenten. MAPE berekent men als het gemiddelde van de niet-ondertekende procentuele fout, zoals weergegeven in het onderstaande voorbeeld:

Veel organisaties richten zich primair op de MAPE bij het beoordelen van de nauwkeurigheid van prognoses. Aangezien de meeste mensen comfortabel denken in procenten, is de MAPE gemakkelijk te interpreteren. Het kan ook informatie overbrengen als u het vraagvolume van het artikel niet kent. Het is bijvoorbeeld zinvoller om tegen uw manager te zeggen “we zaten er minder dan 4% naast” dan te zeggen “we zaten er 3.000 gevallen naast” als uw manager het typische vraagvolume van een artikel niet kent.
De MAPE is schaalgevoelig en is niet bruikbaar bij het werken met gegevens met een laag volume. Merk op dat omdat “Actual” in de noemer van de vergelijking staat, de MAPE ongedefinieerd is wanneer de werkelijke vraag nul is. Bovendien, wanneer de werkelijke waarde niet nul is, maar vrij klein, zal de MAPE vaak extreme waarden aannemen. Deze schaalgevoeligheid maakt de MAPE ondoeltreffend als foutmaatstaf voor gegevens met een laag volume.
MAD
De MAD (Mean Absolute Deviation) meet de grootte van de fout in eenheden. MAD berekent men als het gemiddelde van de niet-ondertekende fouten, zoals weergegeven in het onderstaande voorbeeld:

De MAD is een goede statistiek om te gebruiken bij het analyseren van de fout voor een enkel item; als u echter MAD’s over meerdere items samenvoegt, moet u voorzichtig zijn met producten met een hoog volume die de resultaten domineren – hierover later meer.
De MAPE en de MAD zijn verreweg de meest gebruikte foutenmeetstatistieken. Er is een hele reeks alternatieve statistieken in de prognoseliteratuur, waarvan vele variaties zijn op de MAPE en de MAD. Een paar van de belangrijkste worden hieronder opgesomd:
MAD/gemiddelde verhouding. De MAD/Mean-ratio is een alternatief voor de MAPE dat beter geschikt is voor intermitterende en kleine datavolumes. Zoals eerder vermeld, kunnen procentuele fouten niet worden berekend wanneer de Actual gelijk is aan nul en kunnen ze extreme waarden aannemen bij het omgaan met gegevens met een laag volume. Deze problemen worden nog groter wanneer u het gemiddelde van MAPE’s over meerdere tijdreeksen begint te nemen. De MAD/Mean-ratio probeert dit probleem op te lossen door de MAD te delen door de Mean – in wezen de fout opnieuw te schalen om deze vergelijkbaar te maken over tijdreeksen van verschillende schalen. De statistiek is precies berekend zoals de naam suggereert: het is gewoon de MAD gedeeld door het gemiddelde.
GMRAE
De GMRAE (Geometrische gemiddelde relatieve absolute fout) wordt gebruikt om de voorspellingsprestaties buiten de steekproef te meten. Deze kan men berekenen met behulp van de relatieve fout tussen het naïeve model (d.w.z. de voorspelling voor de volgende periode is de werkelijke waarde voor deze periode) en het momenteel geselecteerde model. Een GMRAE van 0,54 geeft aan dat de grootte van de fout van het huidige model slechts 54% is van de grootte van de fout die wordt gegenereerd met het naïeve model voor dezelfde dataset. Omdat de GMRAE gebaseerd is op een relatieve fout, is deze minder schaalgevoelig dan de MAPE en de MAD.
SMAPE
De SMAPE (Symmetric Mean Absolute Percentage Error) is een variatie op de MAPE die wordt berekend aan de hand van het gemiddelde van de absolute waarde van de werkelijke en de absolute waarde van de voorspelling in de noemer. Deze statistiek heeft door sommigen de voorkeur boven de MAPE en werd gebruikt als nauwkeurigheidsmaatstaf in verschillende voorspellingswedstrijden.
Meetfout voor een enkel item versus meetfouten bij meerdere items
Het meten van de voorspellingsfout voor een enkel item is vrij eenvoudig.
Werkt u met een artikel met een redelijk laag vraagvolume? Dan kan elk van de bovengenoemde foutmetingen worden gebruikt. U moet degene kiezen waar u en uw organisatie zich het prettigst bij voelen. Voor veel organisaties is dit de MAPE of de MAD. Als u met een item met een laag volume werkt, is de MAD een goede keuze. Terwijl de MAPE en andere op percentages gebaseerde statistieken moeten worden vermeden.
Het berekenen van foutmeetstatistieken over meerdere items kan behoorlijk problematisch zijn.
Het berekenen van een geaggregeerde MAPE is een gangbare praktijk. Een mogelijk probleem met deze benadering is dat de items met een lager volume de statistiek kunnen domineren. Deze hebben meestal hogere MAPE’s. Dit is doorgaans niet wenselijk. Een oplossing is om de items eerst te scheiden in verschillende groepen op basis van volume (bijv. ABC-categorisatie). Vervolgens worden er voor elke groep afzonderlijke statistieken berekend. Een andere benadering is om een gewicht vast te stellen voor de MAPE van elk item dat het relatieve belang van het item voor de organisatie weerspiegelt. Dit is een uitstekende praktijk.
Aangezien de MAD een eenheidsfout is, heeft het berekenen van een geaggregeerde MAD over meerdere items alleen zin als vergelijkbare eenheden worden gebruikt. Als u bijvoorbeeld de fout in dollars meet, zal de geaggregeerde MAD u de gemiddelde fout in dollars vertellen.
Samenvatting nauwkeurigheid prognoses
Het volgen van de nauwkeurigheid van prognoses is een essentieel onderdeel van het prognoseproces. Als u de nauwkeurigheid van uw huidige proces niet kunt beoordelen, is het erg moeilijk om het te verbeteren. Bovendien biedt het volgen van de nauwkeurigheid van prognoses inzicht in de verwachte prestaties, kunt u uw prognoses benchmarken en kunt u problemen eerder opsporen, onderzoeken en erop reageren.
Om de nauwkeurigheid bij te houden, moeten we prognoses in de loop van de tijd opslaan, zodat we deze prognoses later kunnen vergelijken met wat er werkelijk is gebeurd. Dit kan worden gedaan in zoiets eenvoudigs als Excel, maar het kan omslachtig zijn voor grote gegevenssets – speciale software wordt aanbevolen.
Wat betreft de metrieken van de voorspellingsnauwkeurigheid, zijn de MAPE en MAD de meest gebruikte foutmetingsstatistieken. Beide kunnen echter onder bepaalde omstandigheden misleidend zijn. De MAPE is schaalgevoelig en voorzichtigheid is geboden bij het gebruik van de MAPE met items met een klein volume. Alle foutmetingsstatistieken kunnen problematisch zijn. Dit is wanneer ze over meerdere items worden geaggregeerd en als voorspeller moet u uw aanpak daarbij goed overdenken.
Forecast Pro is een speciaal softwarepakket. Het is ontworpen om automatisch prognoses voor u te archiveren terwijl de belangrijkste meetstatistieken voor fouten worden berekend. Wil je praten over hoe Forecast Pro jouw prognoseprestaties kan verbeteren? Neem dan contact met ons op.
Originally published at http://www.forecastpro.com/resources/blog/

Plaats een Reactie
Meepraten?Draag gerust bij!