Voorspellen met de Box-Jenkins methode
De Box-Jenkins methode (ARIMA) is een belangrijke voorspellingsmethode die zeer nauwkeurige voorspellingen kan opleveren voor bepaalde soorten gegevens. In deze aflevering van Forecasting 101 onderzoeken we de voor- en nadelen van Box-Jenkins-modellering, geven we een conceptueel overzicht van hoe de techniek werkt en bespreken we hoe we deze het beste kunnen toepassen op bedrijfsgegevens.
Een beetje geschiedenis
In 1970 populariseerden George Box en Gwilym Jenkins ARIMA-modellen (Autoregressive Integrated Moving Average) in hun baanbrekende leerboek Time Series Analysis: Forecasting and Control1. Technisch gezien is de voorspellingstechniek die in de tekst wordt beschreven een ARIMA-model, hoewel veel voorspellers (inclusief de auteur) de uitdrukkingen “ARIMA-modellen” en “Box-Jenkins-modellen” door elkaar gebruiken.
ARIMA-modellen zorgden aanvankelijk voor veel opwinding in de academische gemeenschap, vooral vanwege hun theoretische onderbouwing, waaruit bleek dat als aan bepaalde aannames werd voldaan, de modellen optimale voorspellingen zouden opleveren.
In het begin werd de techniek niet op grote schaal gebruikt door het bedrijfsleven. Dit was vooral te wijten aan de moeilijke, tijdrovende en zeer subjectieve procedure beschreven door Box en Jenkins om de juiste vorm van het model voor een bepaalde dataset te identificeren. Tot overmaat van ramp hebben empirische onderzoeken aangetoond dat, ondanks de theoretische superioriteit van het ARIMA-model ten opzichte van andere voorspellingsmethoden, de modellen in de praktijk NIET routinematig beter presteerden dan andere tijdreeksmethoden.
Afvlakkingsmodellen
Uit een bijzonder belangrijk empirisch onderzoek bleek dat exponentiële afvlakkingsmodellen 55% van de tijd beter presteerden dan Box-Jenkins op een steekproef van 1.001 datasets2. Dit is nog steeds een goed resultaat voor Box-Jenkins (het presteerde in 45% van de gevallen beter dan exponentiële afvlakking), dus de les hier is dat je idealiter zou wisselen tussen verschillende benaderingen, in plaats van een one-size-fits-all benadering te kiezen. .
De uitdaging voor een bedrijfsvoorspeller is om te bepalen welke datasets het meest geschikt zijn voor Box-Jenkins en vervolgens de juiste vorm van het model te identificeren.

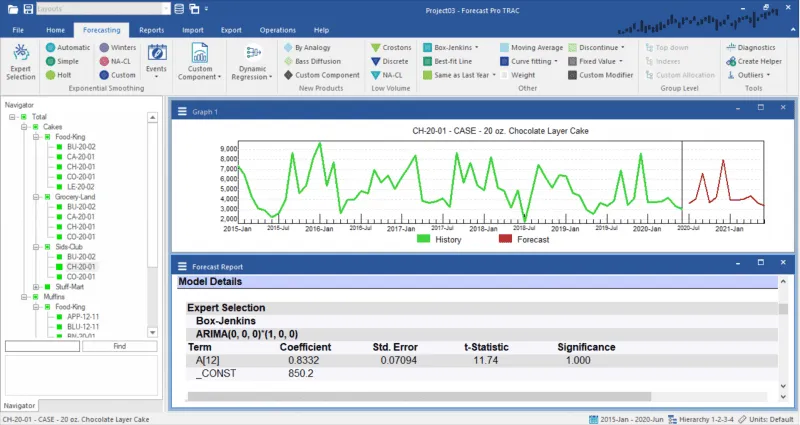
De bovenstaande schermafbeelding toont de prognose die is gegenereerd op basis van een ARIMA-model, samen met de expertselectielogica en modeldetails.
Tegenwoordig gebruiken softwarepakketten zoals Forecast Pro automatische algoritmen om te beslissen wanneer Box-Jenkins-modellen moeten worden gebruikt en om automatisch de juiste vorm van het model te identificeren. Het is aangetoond dat deze automatische benaderingen beter presteren dan de handmatige identificatieprocedures en Box-Jenkins-modellen toegankelijk en bruikbaar hebben gemaakt voor de zakelijke voorspellingsgemeenschap.
Conceptueel overzicht
Hoewel er multivariabele vormen van ARIMA-modellen bestaan, wordt de methode in het bedrijfsleven vooral gebruikt als techniek voor het voorspellen van tijdreeksen. (Tijdreeksmethoden zijn prognosetechnieken waarbij de prognose uitsluitend wordt gebaseerd op de geschiedenis van het item dat u voorspelt.)
Als tijdreekstechniek zijn ARIMA-modellen geschikt als u kunt uitgaan van een redelijke mate van continuïteit tussen het verleden en de toekomst. De modellen zijn het meest geschikt voor voorspellingen op de kortere termijn – bijvoorbeeld 18 maanden of minder – vanwege hun veronderstelling dat toekomstige patronen en trends op de huidige patronen en trends zullen lijken. Dit is een redelijke veronderstelling op de korte termijn, maar wordt zwakker naarmate u verder van de voorspelling uitgaat.
Box-Jenkins-modellen lijken op exponentiële afvlakkingsmodellen in die zin dat ze adaptief zijn, trends en seizoenspatronen kunnen modelleren en kunnen worden geautomatiseerd. Ze verschillen doordat ze gebaseerd zijn op autocorrelaties (patronen in de tijd) in plaats van op een structureel beeld van niveau, trend en seizoensinvloeden. Box-Jenkins heeft de neiging beter te slagen dan exponentiële afvlakking voor langere, stabielere datasets en niet zo goed voor luidruchtigere, meer vluchtige data.
Box-Jenkins-modellen zijn wiskundig complex. In dit artikel zullen we een heel basaal conceptueel overzicht geven van hoe een ARIMA-model werkt en enkele notaties introduceren die bij het model horen. Als u meer wilt weten over Box-Jenkins-modellen: deze worden gedetailleerd besproken in de Forecast Pro Statistical Reference Manual en in vrijwel elk academisch leerboek over tijdreeksvoorspellingen.
ARIMA-model
Een ARIMA-model bestaat uit 3 componenten, die elk helpen bij het modelleren van verschillende soorten patronen. De “AR” staat voor autoregressief. De ‘ik’ staat voor geïntegreerd. De “MA” staat voor voortschrijdend gemiddelde. Elke component heeft een bijbehorende modelvolgorde die aangeeft hoe groot de component is.
In het algemeen wordt een niet-seizoensgebonden Box-Jenkins-model gesymboliseerd als ARIMA(p,d,q) waarbij “p” het aantal AR-termen aangeeft, “d” de volgorde van differentiatie aangeeft en “q” het aantal MA-termen aangeeft. voorwaarden. Een seizoensgebonden Box-Jenkins-model wordt gesymboliseerd als ARIMA(p,d,q)*(P,D,Q), waarbij de p,d,q de modelorders aangeeft voor de kortetermijncomponenten van het model en P,D ,Q geeft de modelorders aan voor de seizoenscomponenten van het model.
Om de juiste Box-Jenkins-modellen te identificeren, moeten de modelorders worden bepaald. Theoretisch zouden de modelorders alle gehele waarden kunnen aannemen; in de praktijk zijn ze meestal 0, 1, 2 of 3. Dit levert nog steeds honderden verschillende modellen op om te overwegen – een van de redenen waarom het handmatig identificeren van de modellen zo moeilijk is.
Samenvatting Box-Jenkins methode
Box-Jenkins is een belangrijke voorspellingsmethode die voor bepaalde soorten gegevens nauwkeurigere voorspellingen kan genereren dan andere tijdreeksmethoden. Zoals oorspronkelijk geformuleerd, berustte de identificatie van modellen op een moeilijke, tijdrovende en zeer subjectieve procedure.
Tegenwoordig gebruiken softwarepakketten zoals Forecast Pro automatische algoritmen om zowel te beslissen wanneer Box-Jenkins-modellen moeten worden gebruikt als om automatisch de juiste vorm van het model te identificeren. Deze automatische benaderingen hebben Box-Jenkins-modellen toegankelijk en nuttig gemaakt voor de gemeenschap van zakelijke prognoses.
OVER DE AUTEUR
Eric Stellwagen is de mede-oprichter van Business Forecast Systems, Inc. en de co-auteur van de Forecast Pro-softwareproductlijn. Met meer dan 29 jaar ervaring wordt hij algemeen erkend als een leider op het gebied van business forecasting. Hij heeft uitgebreid overlegd met veel toonaangevende bedrijven. Waaronder Coca-Cola, Procter & Gamble, Merck, Blue Cross Blue Shield, Nabisco, Owens-Corning en Verizon. Dit om hen te helpen hun prognose-uitdagingen aan te pakken. Eric heeft workshops gegeven voor verschillende organisaties, waaronder APICS, het International Institute of Forecasters (IIF), het Institute of Business Forecasting (IBF), het Institute for Operations Research and the Management Sciences (INFORMS) en de University of Tennessee. Hij is momenteel lid van de raad van bestuur van het IIF en de praktijkadviesraad van Foresight: The International Journal of Applied Forecasting.
Originally published at http://www.forecastpro.com/resources/blog/
Plaats een Reactie
Meepraten?Draag gerust bij!